本模組使用 Google 提供的 ML Kit 套件 Copyright 2022 Google LLC. All rights reserved.
Licensed under the Apache License, Version 2.0 (the “License”); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an “AS IS” BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
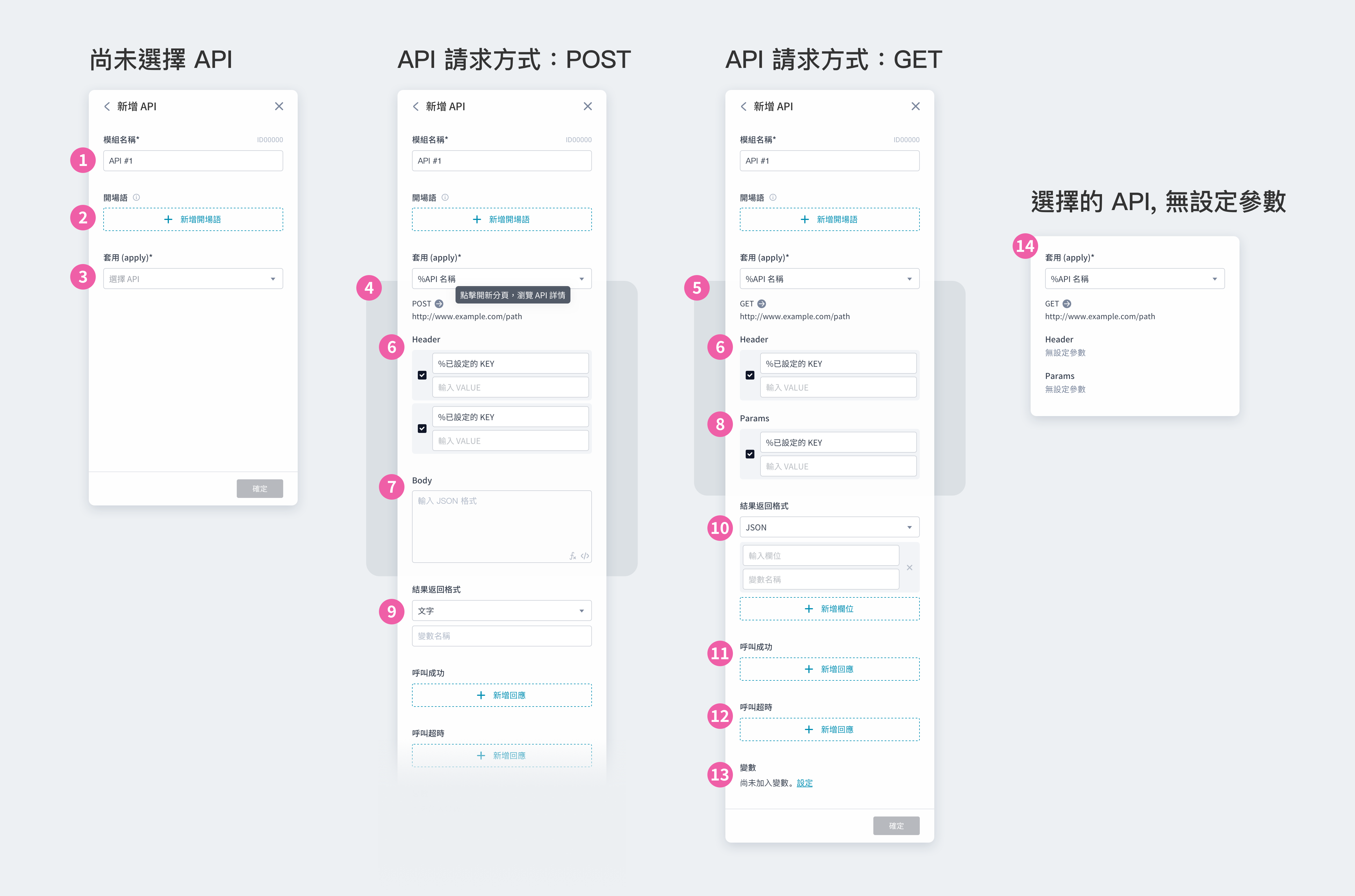
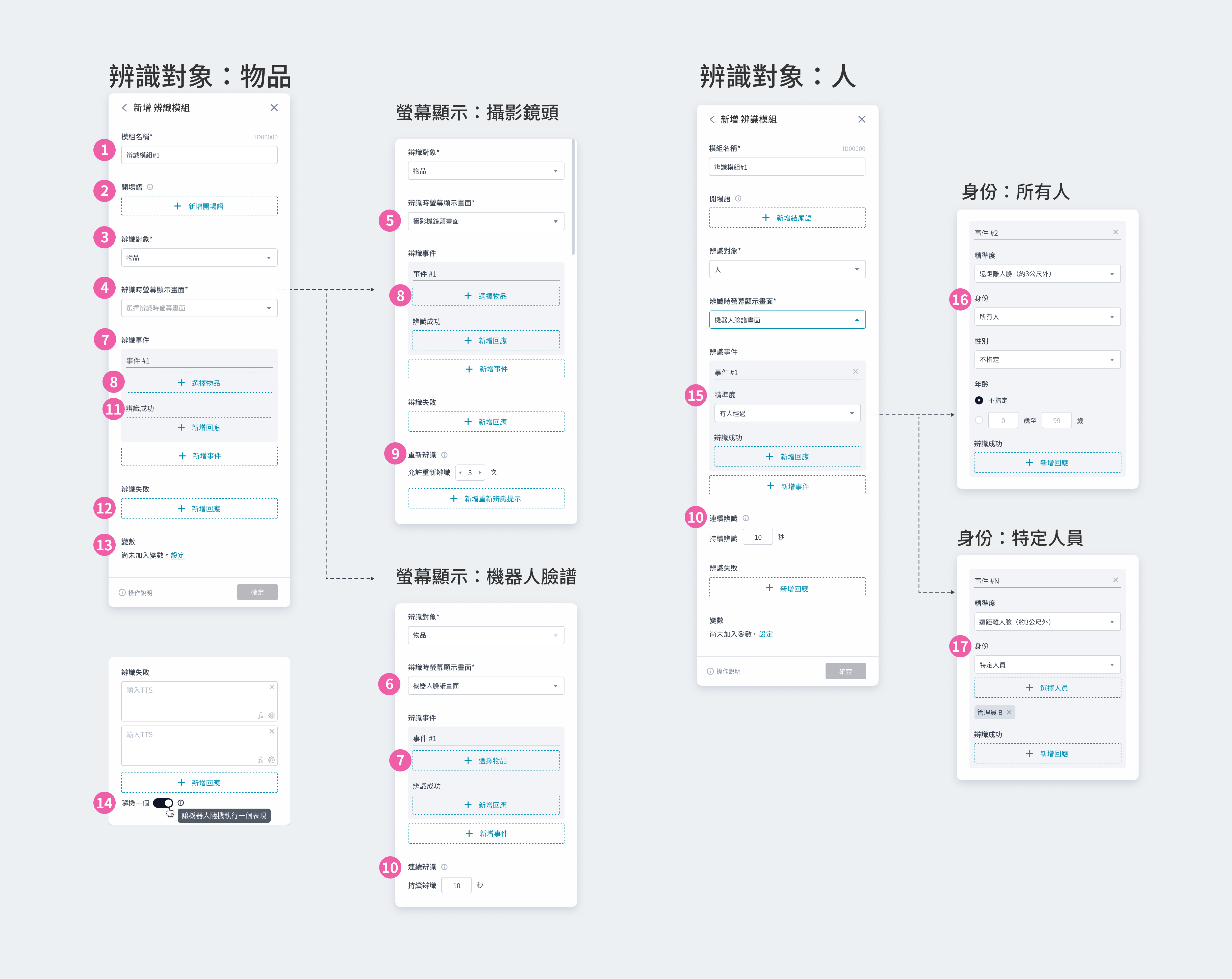
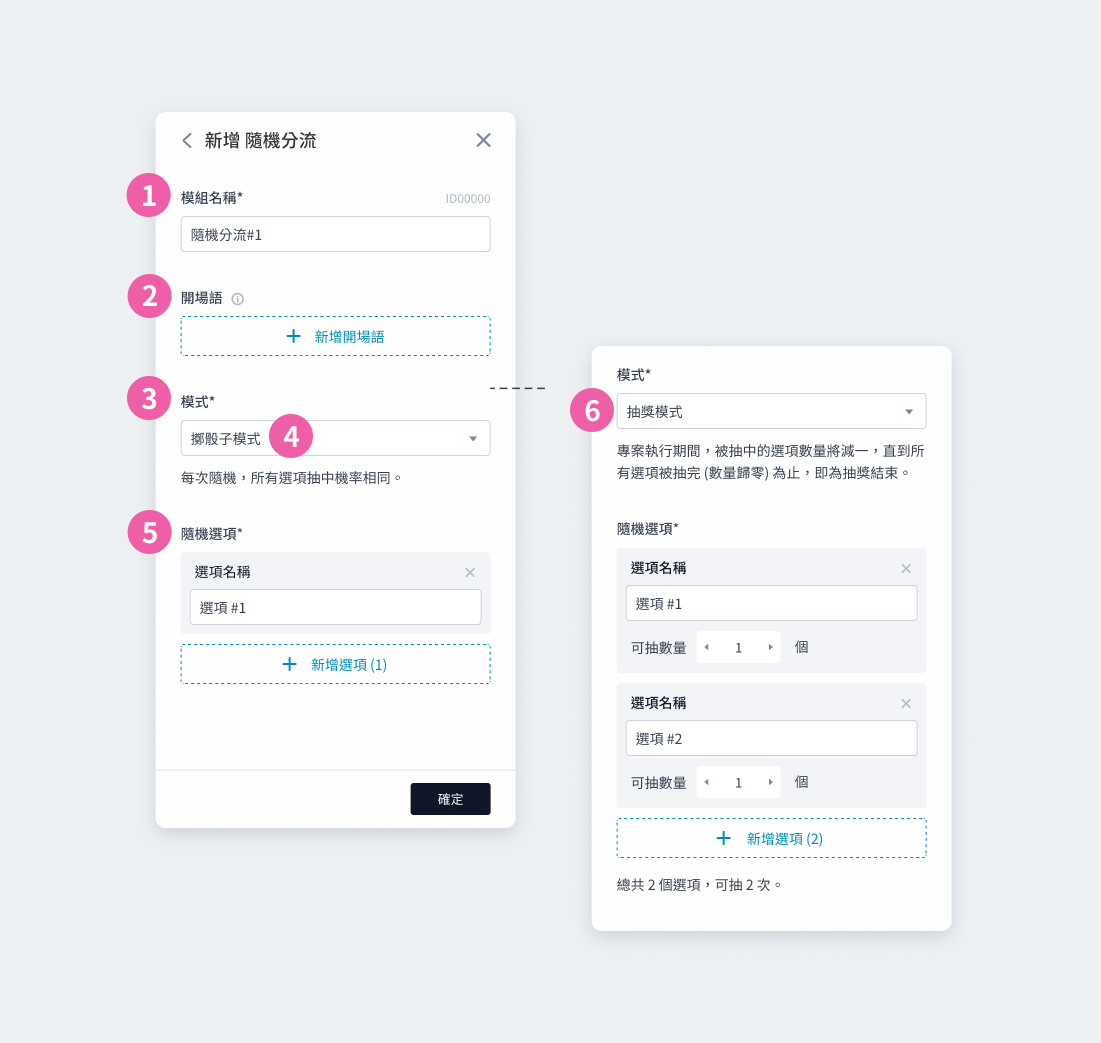
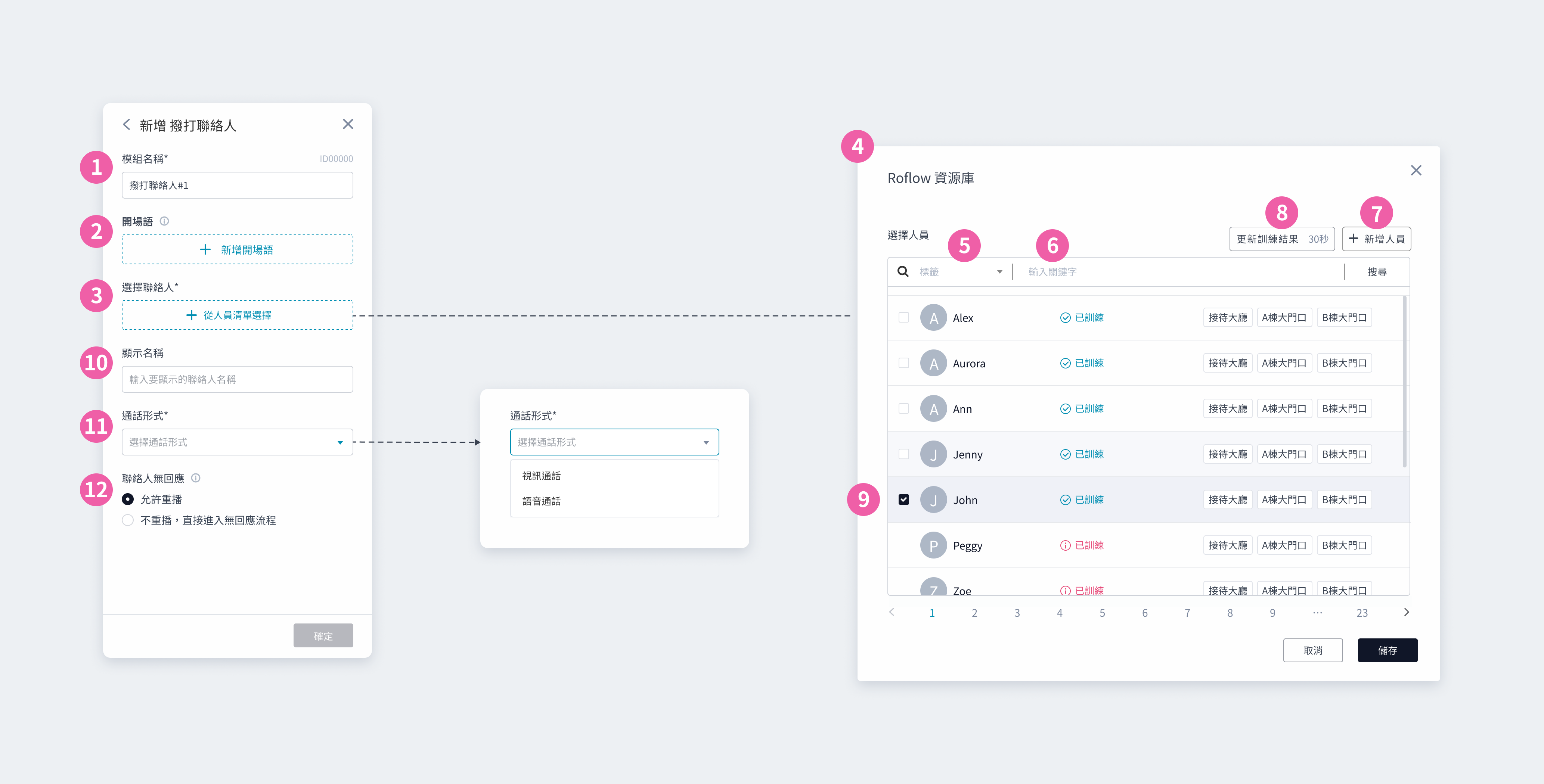
① 模組名稱:會顯⽰在模組卡片上,可⾃訂名稱⽅便識別 ② 開場語:設定一到多個開場語,讓機器人依序說出 ③ 模式:可以選擇擲骰子模式或是抽獎模式 ④ 擲骰子模式:可自訂選項與名稱,所有選項每次抽中機率相同 ⑤ 隨機選項:可自訂選項數量與名稱 ⑥ 抽獎模式:可自訂選項數量與名稱,各選項可再設定不同的可抽數量
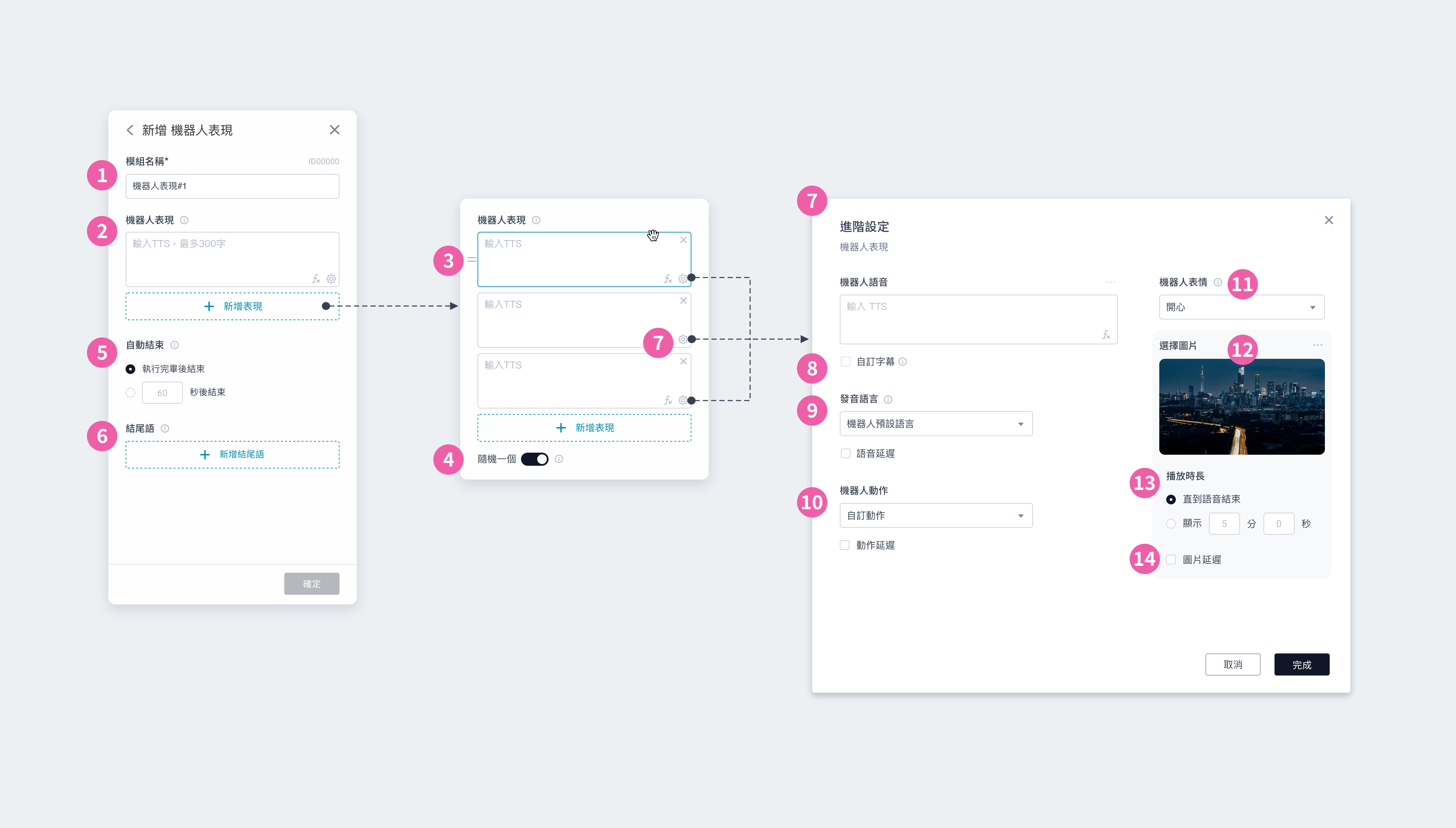
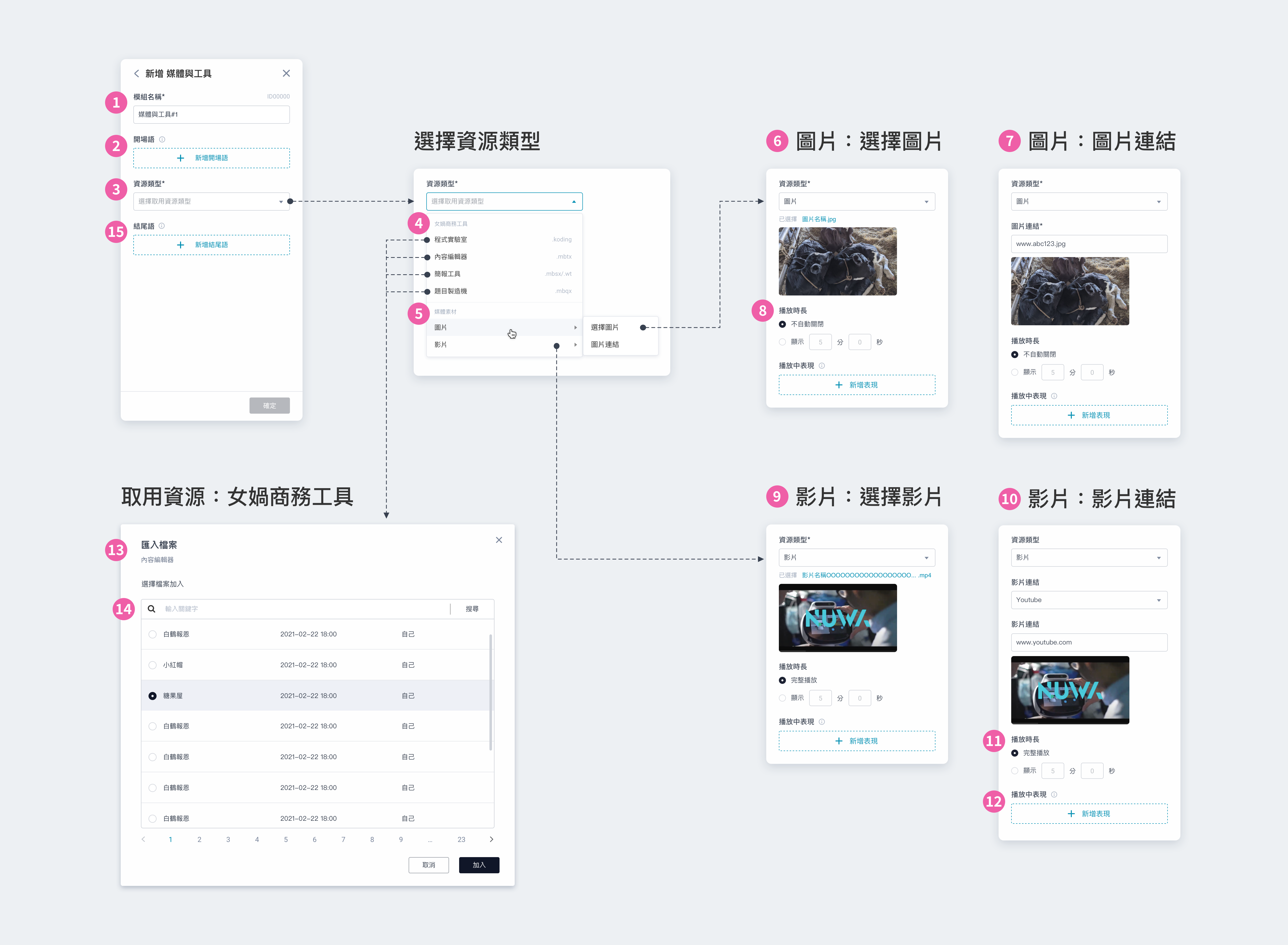
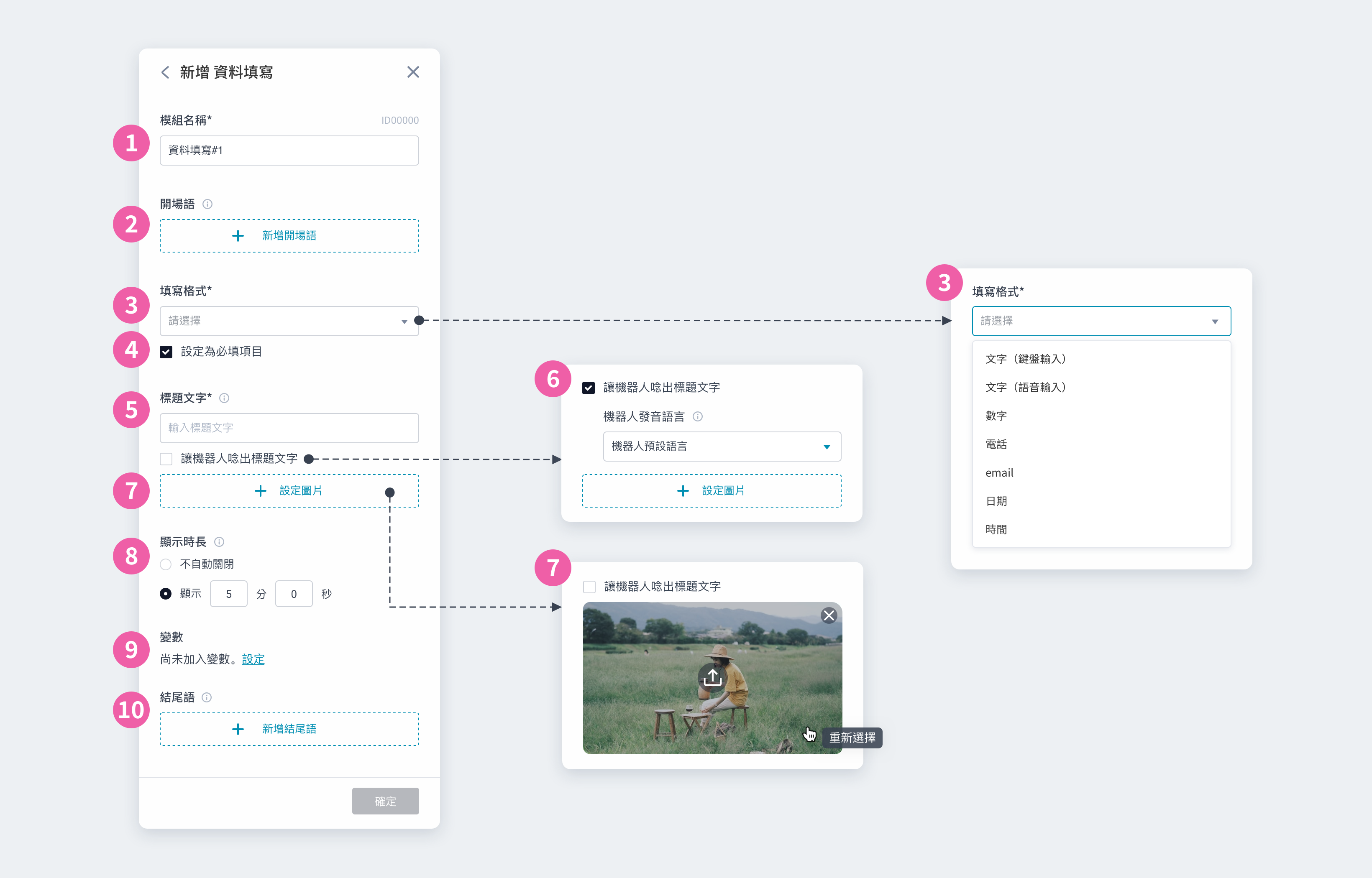
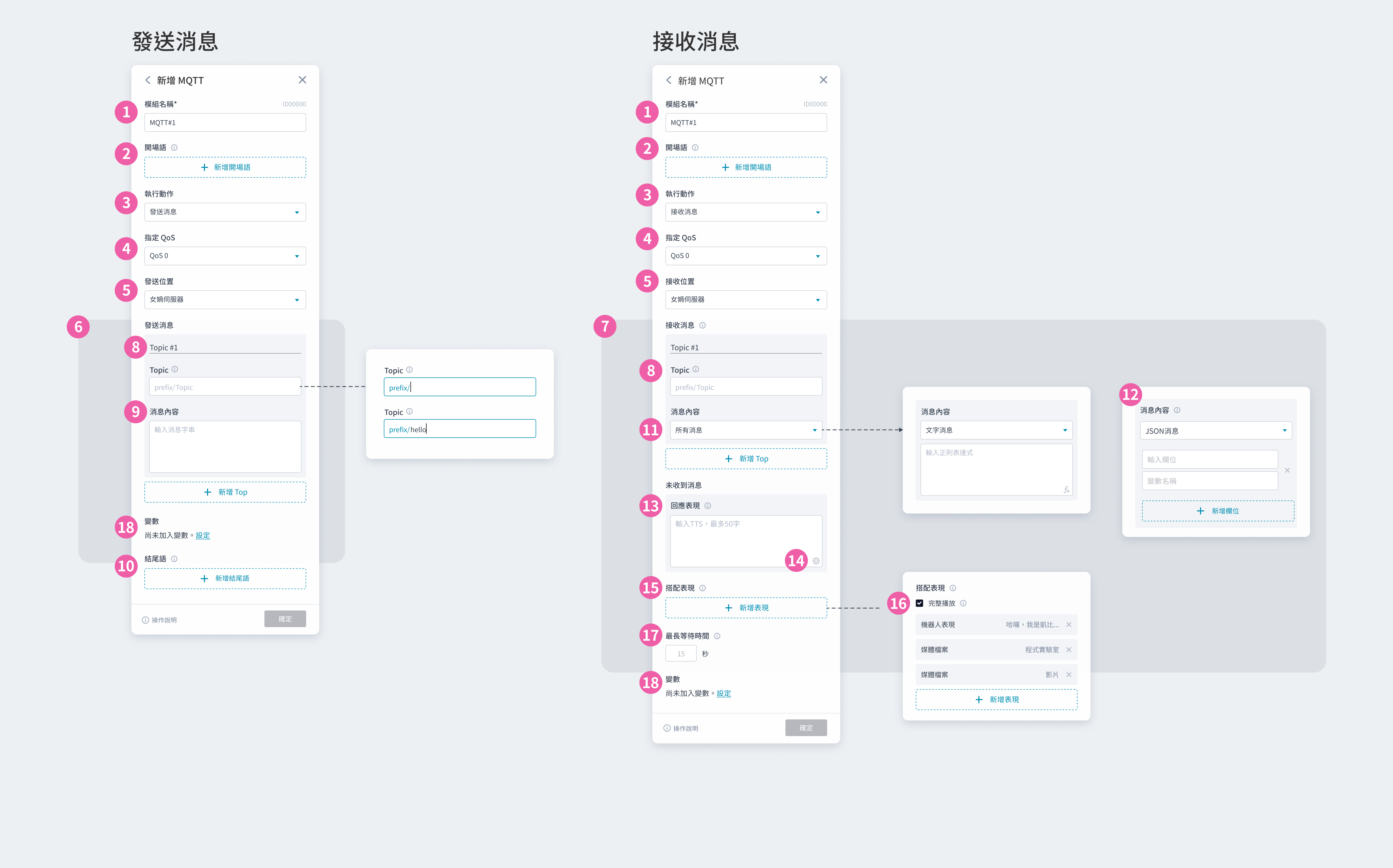
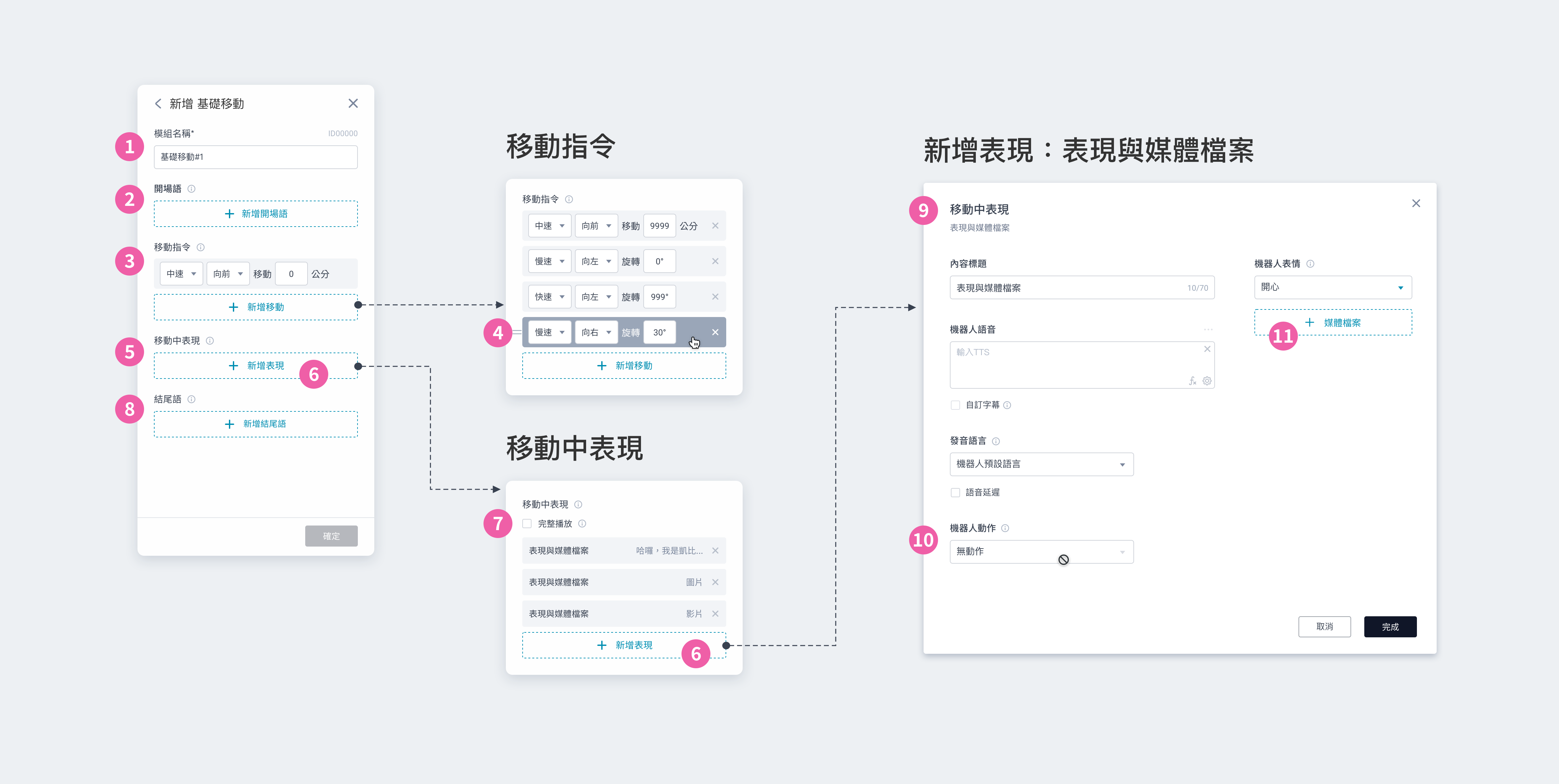
① 模組名稱:會顯⽰在模組卡片上,可⾃訂名稱⽅便識別 ② 開場語:設定⼀到多個開場語,讓機器⼈依序說出 ③ 移動指令:可新增 1~20 個移動指令,將由上⽽下依序執⾏;每個移動指令皆可設定速度、⽅向等數值 ④ 調整移動指令的順序:上下拖曳來調整執⾏的順序 ⑤ 移動中表現:可新增 0~20 個機器⼈表現/媒體內容,將依序播放;若不設定,將呈現機器⼈預設表情 ⑥ 新增表現:新增「⑨ 表現與媒體檔案」 ⑦ 完整播放:⼀般情況下,當機器⼈抵達⽬的地,將立即結束播放。勾選後,則會在完整播放所有表現內容後,才唸出結尾語 ⑧ 結尾語:設定⼀到多個結尾語,讓機器⼈依序說出 ⑨ 表現與媒體檔案:可設定機器⼈表現並搭配媒體檔案。外接雙螢幕時,若有指定媒體檔案,機器⼈螢幕會顯⽰設定的表情 ⑩ 機器⼈動作:無動作,機器⼈移動時無法執⾏動作 ⑪ 媒體檔案|檔案類型:可擇⼀搭配圖片或影片
室內定位移動
服務型機器人(機器人型號 Collibot)專屬限定模組。
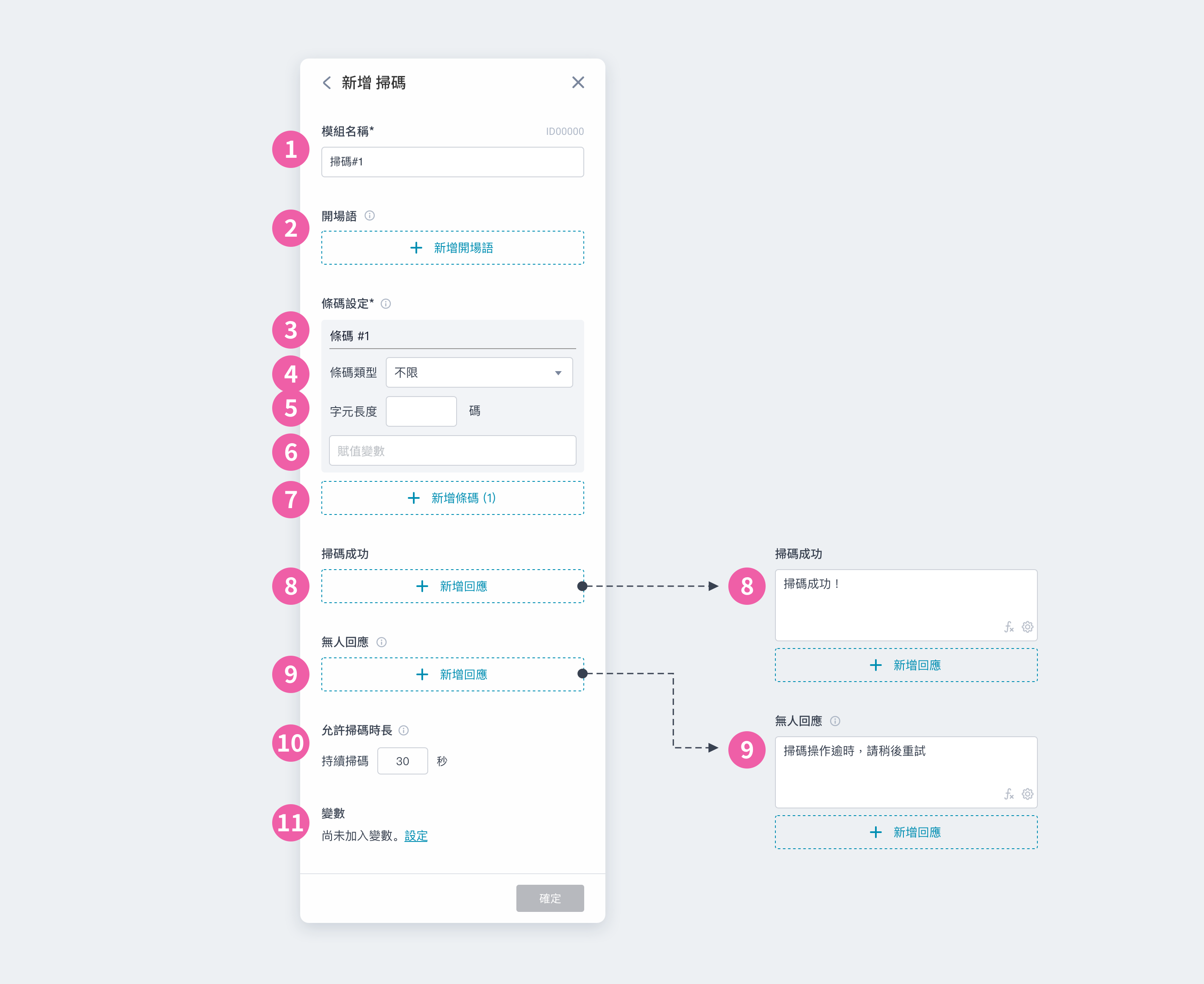
① 模組名稱:會顯⽰在模組卡片上,可⾃訂名稱⽅便識別 ② 開場語:設定⼀到多個開場語,讓機器⼈依序說出 ③ 目的地:此處帶入專案已設定的地圖資訊,可選擇其地標作為目的地;每個專案可指定一個地圖,或「使用機器人地圖」,若要變更地圖設定,須至「專案設定|機器人設定 ⑨」頁面更改 ④ 使用機器人地圖|輸入地標:自行輸入地標名稱,地標欄位支援變數輸入。 ⑤ 指定地圖|指定地標:選擇一個地標作為目的地,只能選擇該地圖中存在的地標。 ⑥ 移動中表現:可新增 1~5 個機器人表現/媒體內容,將依序播放;若不設定,將呈現機器人預設表情 ⑦ 完整播放:一般情況下,當機器人抵達目的地,將立即結束播放;勾選後,則會在完整播放所有表現內容後,才唸出結尾語 ⑧ 結尾語:設定⼀到多個結尾語,讓機器⼈依序說出 ⑨ 地圖設定:在「專案設定|機器人設定」設定專案的「專案地圖」 ⑩ 專案地圖 (Collibot):若選擇「使用機器人地圖」,可參考將執行專案的機器人其搭載的地圖來自訂地標名稱,若多台機器人搭載的地圖皆有相同地標,則同一個專案將可泛用至不同機器人,不需分別下載/變更專案地圖。若選擇「指定地圖」,則需先於資源庫下載地圖,設定時只能選擇該地圖中存在的地標。 ⑪ 預覽地圖:選擇指定地圖後,可放大預覽該地圖,若選擇「使用機器人地圖」則不支援預覽
API
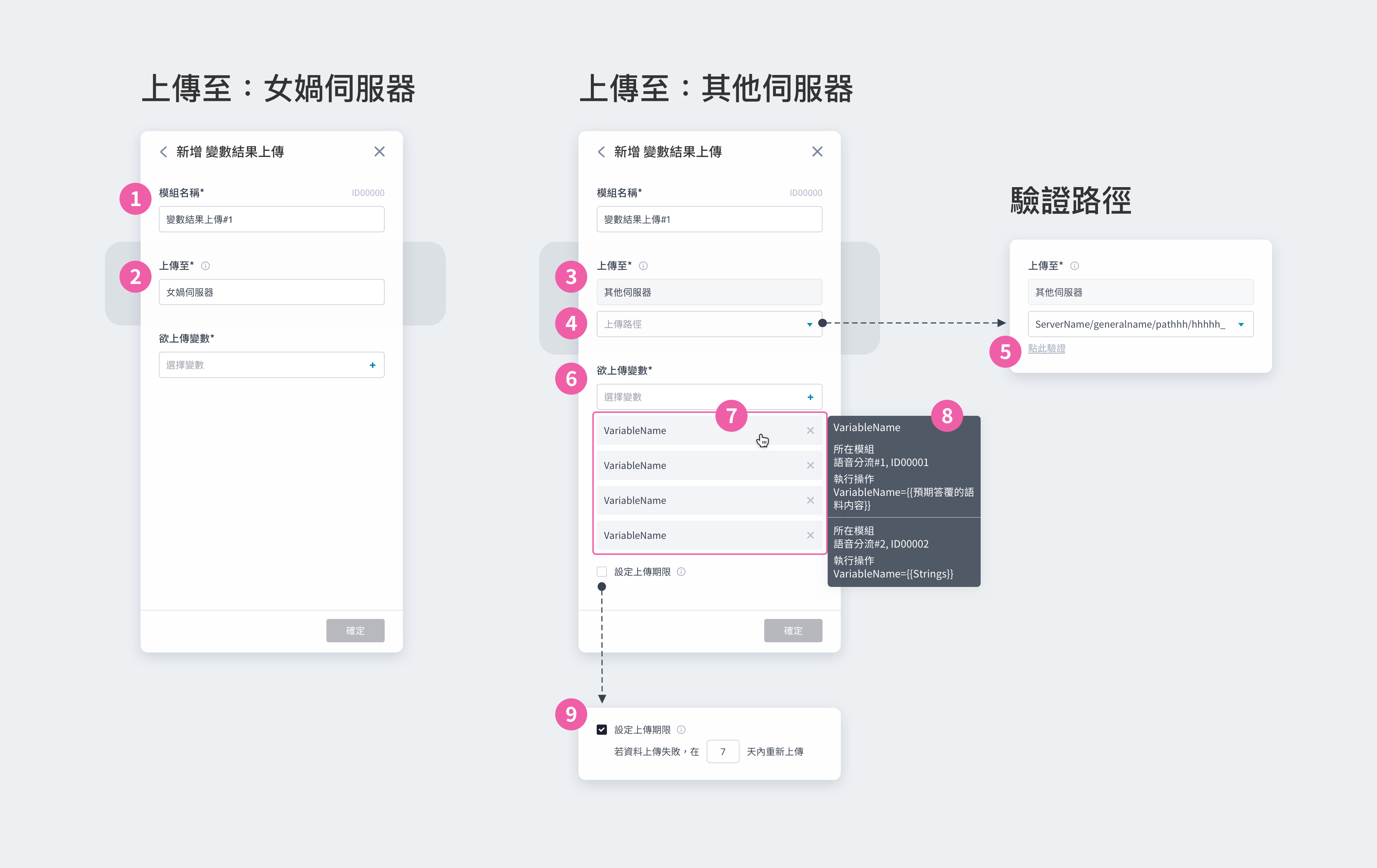
使用此模組前,須先在資源庫新增 API 資料,即可在此模組套用一個 API,輸入相應資料或加入變數組合後,於流程中帶入執行。建議使用此模組前,須有相關知識或有專業人員協助。
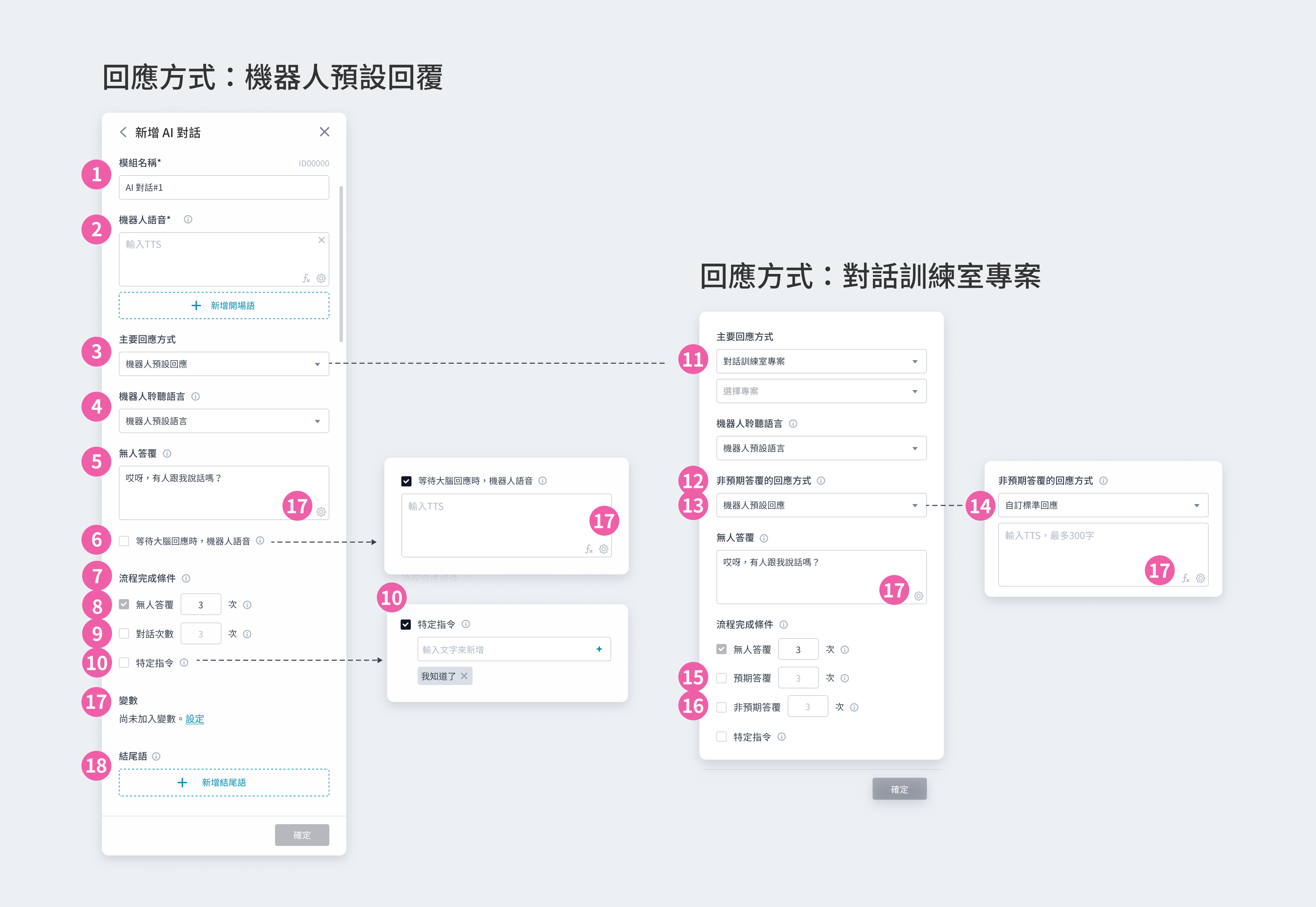
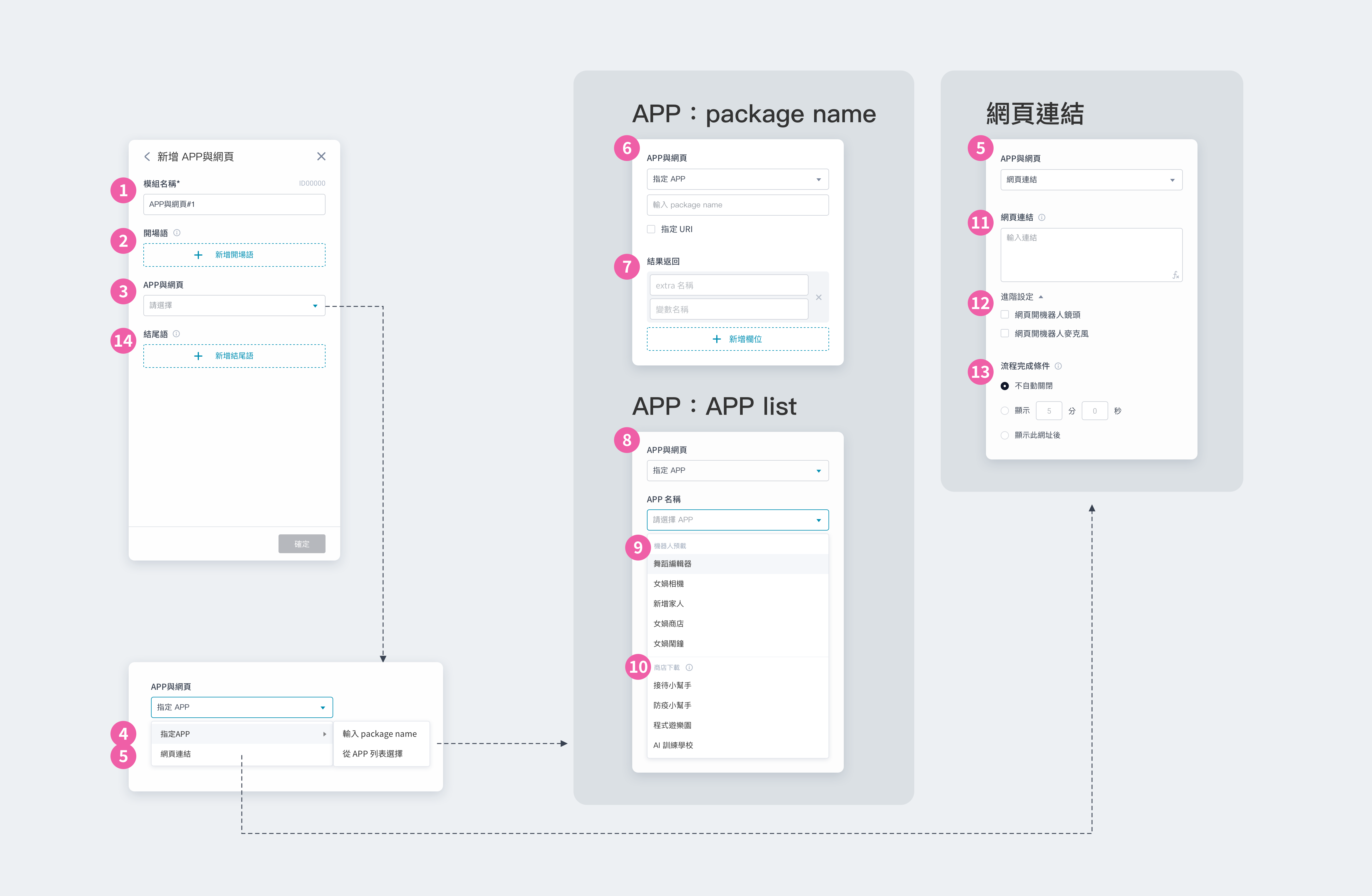
① 模組名稱:會顯⽰在模組卡片上,可⾃訂名稱⽅便識別 ② 開場語:設定⼀到多個開場語,讓機器⼈依序說出 ③ 套用 (apply):選擇本模組欲套用的 API。套用前,請先至資源庫新增 API 資料 套用後,根據 API 的請求方式為 POST/GET,進行不同設定 ④ 套用 API (POST):需設定 Header, Body ⑤ 套用 API (GET):需設定 Header, Params ⑥ 移Header:勾選欲套用的 Header。此處帶入已設定的 KEY,並可設定 VALUE ⑦ Body:輸入 JSON 格式或加入變數,可點擊右下角按鈕 </> 來格式化 JSON 文本 ⑧ Params:勾選欲套用的 Params。此處帶入已設定的 KEY,並可設定 VALUE




-1.png)